researchub
这是一个投研平台,本质是jupyter lab;
我对该模块的定义是存放,我们数据分析的各类notebook文件,以及各种测试代码,相关回测逻辑,请阅读plutus.research模块;
目前有如下demo:
├─0 Build Ideas
│ quantization.emmx
│
├─1 Data
│ ├─data_collection
│ │ export_data_from_clickhouse_to_arrow.ipynb
│ │ export_data_from_clickhouse_to_parquet.ipynb
│ │ export_data_from_clickhouse_to_parquet_by_sql.ipynb
│ │ import_data_from_parquet_to_clickhouse.ipynb
│ │
│ └─data_wrangling
│ │ alter_raw_data_clickhouse.ipynb
│ │ commercial_data_to_clickhouse.ipynb
│ │ download_data_to_parquet.ipynb
│ │ drop_duplicate_data_clickhouse.ipynb
│ │ pretreat_data_to_clickhouse.ipynb
│ │ proccess_data_to_clickhouse.ipynb
├─3 Research
│ ├─cross_section_factor_analysis
│ │ cs_factor_analysis_demo.ipynb
│
│ ├─investment_portfolio
│ │ factor_portfolio_analysis.ipynb
│ │ investment_portfolio_analysis.ipynb
│ │ signal_portfolio_analysis.ipynb
│ │
│ └─time_series_factor_analysis
│ example.ipynb
│ ts_factor_daily_demo.
│ ts_factor_min_demo.ipynb
│
└─5 Trader and Oversight
单因子分析流程(供参考)
引入相应模块
# coding: utf-8
import pandas as pd
import numpy as np
from plutus.research.backtest.backtest import BacktestCS
from plutus.utils.visualization.plot import PlotCS
np.set_printoptions(suppress=True)
pd.set_option('display.float_format', lambda x: '%.5f' % x)
读取数据
datapath='../../../datahub/raw/cn/stock/md/all_1d.parquet'
data_bfq=pd.read_parquet(datapath)
对数据进行基本的处理
open_ = data_bfq["open"].unstack()
close = data_bfq["close"].unstack()
high = data_bfq["high"].unstack()
low = data_bfq["low"].unstack()
vol = data_bfq["volume"].unstack()
amount = data_bfq["amount"].unstack()
#去除涨跌停,去除停牌股
# tradeable=data_bfq['amount'].apply(lambda x :1 if x>0 else np.nan)*(data_bfq['high']-data_bfq['low']).apply(lambda x :1 if x!=0 else np.nan)*chg_1_d.stack().apply(lambda x :1 if x<0.100 else np.nan)
# tradeable=tradeable.unstack()
#获取基准
# benchmark
merge_data=pd.DataFrame()
# #megedata["period"]=close.pct_change(1).shift(-1).stack()#以收盘价交易
merge_data["period"]=open_.pct_change().shift(-2).stack()#以开盘价交易
merge_data = merge_data[np.isfinite(merge_data).all(1)]
定义一个因子
def factor_simple():
factor=-1*Close.pct_change(5)
return factor
test_factor=factor_simple()
计算factor_rank
backtest_cs= BacktestCS()
clean_factor_data= backtest_cs.cal_factor_rank(merge_data,test_factor)
计算fator_quantile
clean_factor_data= backtest_cs.cal_factor_quantile(clean_factor_data,group_num=20)
选择自己需要的hold_portfolio
long_portfolio_data, short_portfolio_data =backtest_cs.cal_hold_portfolio(clean_factor_data, hold_num= 1)
计算标的权重,可以自己拟定
portfolio_data = backtest_cs.cal_portfolio_weight(long_portfolio_data)
计算回测指标
ret_df, sharpe_ratio, annual_return, max_down= backtest_cs.describer_01(long_portfolio_data,short_portfolio_data)
画出分组累计收益
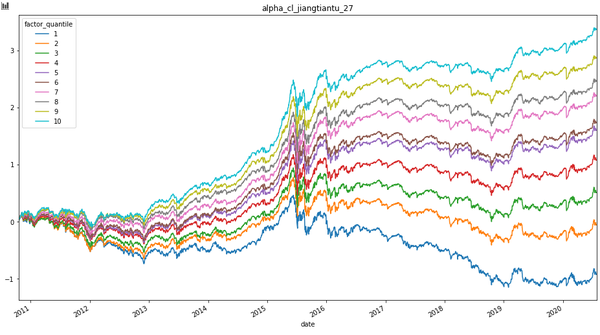
PlotCS.plot_group_cumsum_pnl(clean_factor_data)
画出long-short多空收益
ret_df.plot(figsize=(16, 9), title="test")
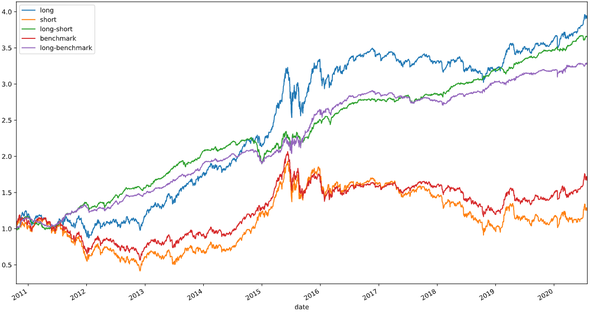
基本上你自己定义一个因子,之后就直接开始研究了。我这个框架是学习alphalens写的,因为alphalens 太慢了,所以,就自己实现了,要快些。没有做任何封装,理解起来容易些。所有曲线没有计算手续费,没有计算对冲成本。
投资组合流程(供参考)
引入相应模块
# coding: utf-8
import plutus.research.backtest.backtest as ba
import pandas as pd
import numpy as np
import empyrical as empl
import matplotlib.pyplot as plt
from plutus.portfolio.portfolio_cal.portfolio_base import PortfolioBase
backtest_cs=ba.BacktestCS()
portfolio_base =PortfolioBase()
读取行情数据
all_1d_df = pd.read_parquet("../../../datahub/raw/cn/stock/md/all_1d.parquet")
all_1d_df.set_index(["trade_date", "code"], inplace=True)
all_1d_df['ret_1d']= all_1d_df['close']/all_1d_df['pre_close']-1
all_1d_df.head()
读取signal数据
all_1d_df = pd.read_parquet("../../../datahub/raw/cn/stock/md/all_1d.parquet")
all_1d_df.set_index(["trade_date", "code"], inplace=True)
all_1d_df['ret_1d']= all_1d_df['close']/all_1d_df['pre_close']-1
all_1d_df.head()
计算每日收益
all_pnl_1d_df = all_signal_df.groupby(['name','trade_date'])['pnl_1d'].mean()
all_pnl_1d_df=all_pnl_1d_df.unstack().T
all_pnl_1d_df.dropna(inplace=True)
all_pnl_1d_df.head()
筛选出需要的因子(有未来数据)
calmar_ratio_df= portfolio_base.cal_calmar_ratio(all_pnl_1d_df)
select_s = np.where(abs(calmar_ratio_df)>0.5,1,np.nan)
selected_pnl_1d_df = all_pnl_1d_df.mul(select_s,axis=1)
计算因子组合权重(有未来数据)
portfolio_weight_s = portfolio_base.cal_weight(selected_pnl_1d_df)
portfolio_weight_s
计算组合净值收益(有未来数据)
net_s = all_pnl_1d_df.mul(portfolio_weight_s).sum(axis=1)
net_s.cumsum().plot()